M2 MacBook Air 24GBからM5 MacBook Air 32GBに乗り換え — OllamaでローカルLLMの性能を比較してみた
目次
注意事項
- 本記事の内容は試験的な実装であり、アイデアベースの検証です
- 実務での利用を保証するものではありません
- 実装についての責任は負いかねます。自己責任でご利用ください
- AIの出力結果は常に検証が必要です
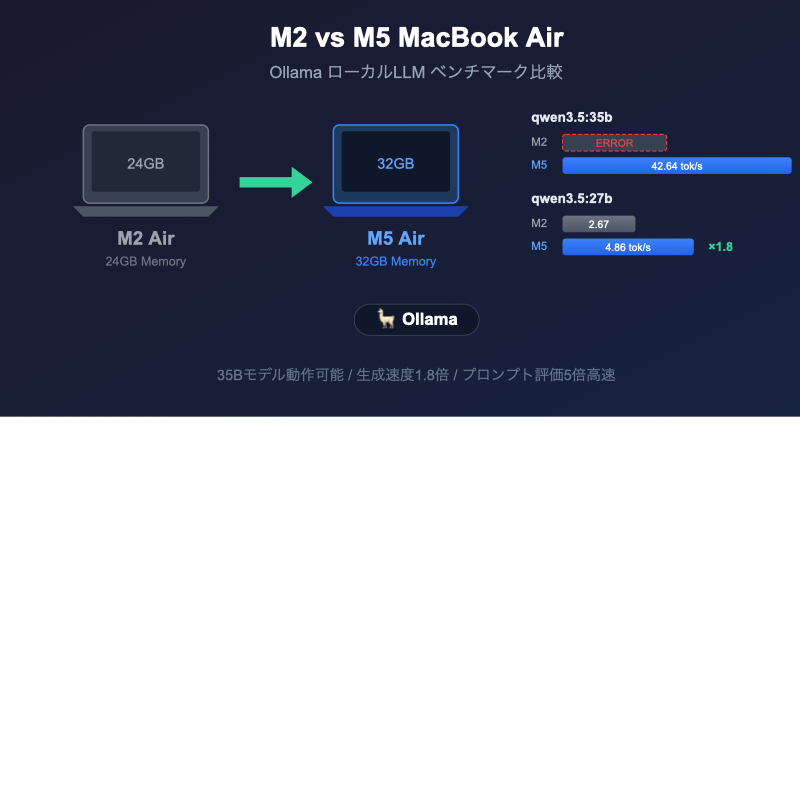
M2 MacBook Air(24GB)からM5 MacBook Air(32GB)に乗り換えたので、ローカルLLMの性能がどれだけ変わるのか、Ollamaを使って実際にベンチマークしてみました。
テスト環境
| 項目 | 旧マシン | 新マシン |
|---|---|---|
| モデル | MacBook Air M2 | MacBook Air M5 |
| メモリ | 24GB | 32GB |
| Ollama | v0.19(MLXバックエンド) | v0.19(MLXバックエンド) |
テストに使用したモデルは以下の2つです:
- qwen3.5:35b-a3b-coding-nvfp4 — 35Bパラメータ、NVFP4量子化のコーディング特化モデル
- qwen3.5:27b — 27Bパラメータの汎用モデル
プロンプトは両方とも同じ「ブログを作りたいので要件定義書を作って」で統一しました。
ベンチマーク結果
qwen3.5:35b-a3b-coding-nvfp4(35Bモデル)
| 指標 | M2 MacBook Air 24GB | M5 MacBook Air 32GB |
|---|---|---|
| 結果 | エラー(メモリ不足) | 正常動作 |
| 総実行時間 | — | 57.2秒 |
| プロンプト評価速度 | — | 15.54 tok/s |
| 生成速度 | — | 42.64 tok/s |
| 生成トークン数 | — | 2,321 tokens |
M2 MacBook Air 24GBでは、モデルのロードに20.4GiBが必要なのに対し、利用可能なメモリが17.3GiBしかなく、起動すらできませんでした。
Error: 500 Internal Server Error: model requires 20.4 GiB but only 17.3 GiB are available (after 512.0 MiB overhead)
M5 MacBook Air 32GBでは問題なく動作し、42.64 tok/sという実用的な速度で生成できました。体感的にもリアルタイムで文章が流れてくるレベルです。
qwen3.5:27b(27Bモデル)
| 指標 | M2 MacBook Air 24GB | M5 MacBook Air 32GB | 改善率 |
|---|---|---|---|
| 総実行時間 | 19分17秒 | 6分11秒 | 3.1倍高速 |
| プロンプト評価速度 | 0.73 tok/s | 3.66 tok/s | 5.0倍 |
| 生成速度 | 2.67 tok/s | 4.86 tok/s | 1.8倍 |
| 生成トークン数 | 3,023 tokens | 1,780 tokens | — |
27Bモデルは両マシンで動作しましたが、性能差は歴然です。M2では生成速度が2.67 tok/sと、1秒に2〜3トークンしか出力されないため、長い回答を待つのがかなり辛い状況でした。M5では4.86 tok/sと約1.8倍に向上し、待ち時間が大幅に改善されました。
特にプロンプト評価速度(入力の処理速度)は0.73 tok/s → 3.66 tok/sと5倍の改善で、応答開始までの待ち時間が大きく短縮されています。
生成された回答の品質
興味深いことに、同じプロンプトに対して両モデル・両マシンとも「ブログ要件定義書のテンプレート」を生成しましたが、出力のスタイルに違いがありました。
35Bモデル(M5のみ)
- Thinking(思考過程)が英語で出力される
- 日本語の出力は自然で読みやすい
- 要件定義書の構成が実用的
27Bモデル(M2 vs M5)
- 両方ともThinkingが日本語で詳細に出力される
- M2では3,023トークン、M5では1,780トークンと出力量に差があるが、これはモデルの生成のばらつきによるもの
- 内容の品質自体はほぼ同等
まとめ
| 観点 | M2 MacBook Air 24GB | M5 MacBook Air 32GB |
|---|---|---|
| 35Bモデル | 動作不可 | 快適に動作(42.64 tok/s) |
| 27Bモデル | 動作するが遅い(2.67 tok/s) | 実用レベル(4.86 tok/s) |
| プロンプト評価 | 非常に遅い(0.73 tok/s) | 5倍高速(3.66 tok/s) |
M2からM5への乗り換えで得られた最大のメリットは以下の3点です:
- 35Bモデルが動くようになった — メモリ24GB→32GBの差で、これまで動かせなかったサイズのモデルが利用可能に
- 生成速度が約1.8倍に向上 — 27Bモデルでの比較で、体感できるレベルの高速化
- プロンプト評価が5倍高速 — 応答開始までの待ち時間が劇的に短縮
ローカルLLMを日常的に使う場合、メモリ容量とチップ性能の両方が重要です。特に32GB以上のメモリは、実用的なサイズのモデルを動かすための最低ラインと言えるでしょう。M5 MacBook Airは、ローカルAI用途においてコストパフォーマンスの高い選択肢です。